Java总结面试题
一、Redis
1、分布式锁
解决分布式线程安全问题
在单体项目中一般是使用同步锁ynchronized锁保证线程安全,但是分布式情况下,由于同步锁是JVM级别只能锁住单个线程,所以一开始可以使用redis或者zookeeper进行分布式锁
- 一开始使用Redis作为分布式锁,可以采用setnx并且设置过期时间,但如果一个持有setnx的服务器在锁过期之后还是没有处理完业务
- 可以加长一个过期时间,并且设置子线程每n秒去确认线程是否在线,在线则将过期时间重设
- 给锁加一个UUID
- 上面这些功能实现复杂,可以使用Redisson
Redission原理

在进入到Redis主从集群的时候需要注意,由于Redis是保证AP高可用的,所以当Master获取到锁之后就会返回,然后再进行同步,所以这里为了保证CP高一致性,则需要设置red lock保证同步到所有节点都获取到锁之后再进行返回
2、缓存击穿、缓存雪崩、缓存穿透
2.1、缓存击穿
缓存击穿是由于热点Key的失效,处理上可以分成几点。
-
简单的方式:比如对于一些热门的数据可以设置永不过期、对于一些冷门数据如果在一定时间内突然并发很高,可以进行监控使用redis进行计数,如果这个数量大于设定的阈值了可以进行设置一个较长时间不过期的Key。
-
加锁排队:并发量很高的时候可以加个锁,当第一个线程将数据放到redis之后,再释放锁。这里可以使用synchronized同步锁,其中使用双重检查锁(DCL)的代码逻辑处理
分布式锁:上面所提到使用加锁排队其实是在非微服务模块
还有可能是因为缓存没有提前预热,可以跑一遍单元测试进行预测
也可以进行限流,使用令牌桶和漏桶
也可以使用多级缓存
2.2、缓存雪崩
缓存集中过期,或者缓存服务宕机,导致大量请求访问数据库,造成数据库压力过大,宕机
- 对于集中过期:可以在加锁排队上添加一个Random的随机过期时间,让其不在同一时间内过期
- 对于服务宕机:redis高可用
2.3、缓存穿透
请求数据库不存在、缓存也不存在的数据
- 参数校验
- 缓存空对象
- 布隆过滤器:黑名单、白名单
3、延迟双删
4、一亿用户积分排行榜
可以使用redis中的zset进行,可以自动进行排序,但是由于数据量过大的时候,这个key会变成一个大Key,此时需要进行分桶治之
1 | reverseRangeWithScores(RANKING_KEY,start:O,end:n - 1) |
5、Redis应用场景
string、hash、list、set、zset
-
string:分布式锁、
-
hash:商品购物车、存储对象信息
-
list:微信公众号、微博信息流、消息队列
-
set:微信小程序抽奖(使用srandomember xxx无放回,spop有放回)、朋友圈点赞、微博和抖音(共同关注、我关注的人也关注他、我可能认识的人采用sinter、sismember、sdiff)
-
zset:有序的、可做排行榜、微博的热点信息
-
bitmap
-
geo:用于查询附近的人,或者附近的商店商品等,使用经纬度进行定位。
-
hyperloglog:统计网站的独立访客量
6、微信社交模型及其推流
我和xx的共同关注、我关注的人也关注他、我可能认识的人
7、Zset
底层有两种实现方式:
- 压缩列表:ziplist,时间复杂度为O(N)、占用空间较少
- 跳表:skipList,时间复杂度为O(log(N)),类似于B+Tree,建立索引,从底层开始往上有冗余索引、占用空间较大
8、缓存和数据库数据一致性
解决这种方式需要考虑业务场景是AP还是CP,是强一致性和最终一致性
- 先删除redis再更新数据库
- 使用synchronized锁,但是会使性能下降
- 使用canal监控binlog日志,当log日志更新后再更新redis数据,但是这种方式还是无法确保完全的数据一致性
强一致性:
使用加锁的方式能够保证强一致性
最终一致性:
- 先删除缓存,再更新数据库,此时如果在更新数据库之前有一个请求到了则缓存中的数据会一直是老的数据 :x:
- 先更新数据库,再删除缓存
- 在第二条的基础上添加 延迟双删,即在删除完缓存之后等个几百毫秒再删除一次缓存
- 使用mq,在更新数据库之后发送一条消息到mq中,消费者订阅删除缓存,这种方式更加安全有重试机制,但是引入的中间件,更重了
- 监听binlog日志,在更新完数据库之后,cancel会监听到binglog日志后自动去删除redis缓存数据
9、热点Key
- 分片热点key
- 采用Caffeine、JVM缓存到本地
- 设置热点key监控系统,如果出现某个时间段访问量激增,对这个热点key进行一个缓存
10、Key过期不会立即删除
redis中key过期不会立即删除,会采用惰性删除 + 定期删除
- 惰性删除:等到访问的时候会进行删除
- 定期删除:防止惰性删除不进行,按照自定义的时间周期进行删除
11、Redis持久化
RDB和AOF
- RDB:会定时将内存中的数据写入到磁盘中,可采用fork子线程bgsave然后采用copy-on-write的方式去保存,不占用主内存
- 一种是save会占用主进程,一种是bgsave会fork子进程
- AOF:将操作的命令存入到磁盘文件,当需要时候只需要重新运行即可,有三种刷盘机制
- always:同步刷盘
- everysec:每秒回写
- no:操作系统控制
12、Redis中数据结构
- String
- List
- Set
- Hash
二、Spring
1、Bean是单例,会不会有线程安全问题
在多线程并发环境下,由于同时对一个共享资源(Bean)进行读写,就会出现线程不安全,问题:(脏读、数据篡改)。但是只要不在单例bean中声明一些共享的类成员变量,并且不对共享资源进行读写,就不会出现线程安全问题
设置成多例:@Scope(“prototype”)
2、@Resource和@Autowired的区别
-
@Resource是JaveEE提供的,@Autowired是由Spring提供
-
@Resource默认是采用名称在容器中查找,当找不到时候再去找类型
@Autowired默认采用类型在容器中查找,如果类型有多个实现的时候,会根据名称查找容器对象
-
@Autowired如果有多个实现的话,并且想要使用自定义名称可以使用@Qulifier进行指定加载的类
3、解释Spring框架中bean的生命周期
4、@EnableSchedule
是Spring框架中的一种注解,用于启动Spring的任务调度功能,允许定义和管理定时任务
通过@Schedule进行定时,@EnableSchedule开启定时服务
5、全局异常处理器
- 首先自定义异常处理器继承RuntimeExecption
- 创建一个返回的信息的包装类RestErrorResponse
- 然后使用自定义拦截器使用@ControllerAdvice和**@ExceptionHandler** 进行拦截,返回RestErrorResponse(自定义的异常类)
6、JSR303规范
对前端传来的数据在Controller层就进行校验,首先需要在Bean种规范Min、Max等,然后在Controller中对于输入的参数使用@Validated进行修饰,如果多个controller使用了同一个model,但是校验返回的信息不同,可以采用分组的方式进行
三、Mysql
MySQL数据库天花板教程,2小时看完直接面试上岗笔记资料:https://www.yuque.com/tulingzhouyu/sfx8p0/qnxql079alg2ghhz?singleDoc#
密码:nfyq
1、索引
索引是帮助Mysql高效获取数据排好序的数据结构
-
二叉树:作为数据结构的话,倘若存储1、2、3、4、5这种递归的数据的时候会造成一个链状结构
-
红黑树:在二叉树上进行了优化,确保左右节点高度相差不超过1,但是随着数据量增加会导致树的高度会很高
-
B树:是将一个节点只能存储一个数据转成可以存储多个数据,从而降低了树的高度
- B树中是将数据和索引都存储到了一个节点中,一个节点只能存储16个
-
B+Tree:是B树的变体,支持范围查找
-
一个节点可以存储1170个
其实在mysql一启动时候就将非叶子节点都加载到了内存中,然后通过折半查找可以定位到叶子节点 ,只进行一次IO操作
-
-
Hash表:不支持范围查找
联合索引
由于最左前缀原则,这里只有第一个查询语句会走索引。比如当只使用age和position的时候由于没有规定name字段,担心会有重复的所以还会进行一次全表扫描,这就是不走索引的原因
2、存储引擎
2.1、MyISAM
底层存储使用三个数据文件:fm(表结构)、MYI(存放的索引)、MYD(存放的数据)
2.2、Innodb
innodb底层存储为两个文件:fm(表结构)、ibd(索引+数据)
- 使用InnoDB引擎如果没有指定索引,则会默认找唯一索引如果唯一索引也没有则会在后台创建一个Rowid放在表的后面用于创建InnoDB的结构
- 如果采用自增主键的话,不推荐分库分表使用,更适合采用雪花算法分布式ID
- 如果使用非主键作为索引,则会二次回表进行查询,可以看图中所示
3、Mysql内部核心组件
- 查询缓存:mysql5.7之前具有查询缓存,会按照
key:value就是对应的sql和数据,但是当表中数据发生update的时候就会删除缓存,非常鸡肋,但是字典表这种就可以使用查询缓存。mysql8.0之后将这个查询缓存删除了。 - 词法分析器:如果通过词法分析器检查无误之后,会将SQL语句放到一个语法树中。
- 优化器:查看哪个字段有索引
- 执行器
4、MySQL分布式架构主键ID
【Java后端开发面试必问:布式ID雪花算法实战,花90分钟看完,java面试直接加分!】 https://www.bilibili.com/video/BV1FPW2z6EUB/?p=4&share_source=copy_web&vd_source=b1cd12cd9d40457a3baf3133ec496e39
MySQL分布式架构主键ID,为什么不能使用自增ID或者UUID做主键,雪花算法生成的主键存在哪些问题
-
自增ID:不推荐当主键,在分布式情况下会导致查表冲突,当查询一个ID为3的数据的时候会在不同的表中查出相同的ID,会导致冲突。
-
UUID:可以当主键但会导致性能下降,在InnoDB引擎下存储方式是B+Tree,由于是有序的,但UUID是无序的所以每次插入新数据会导致整棵树进行重排序,导致性能下降。但mysql8.0新增了一个Bin_UUID会使用低位高位这种保证UUID的有序性
-
雪花算法:全局唯一、趋势递增、信息安全,但是不保证单调递增。雪花算法强依赖于时间戳,存在时钟回拨问题(Linux时间比真实时间快几秒)需要通过网络时间校准和人工设置(这里需要改变机器码或序列化中的组成,添加一个始终序列)
5、InnoDB底层原理
Undo Log、Redo Log 和 Binlog 是 MySQL 中三种不同类型的日志,它们各自有不同的用途和特点:
- Undo Log(撤销日志)
- 用途:用于实现事务的回滚操作,以及支持多版本并发控制(MVCC)。
- 特点:
- 记录的是逻辑修改的逆操作,即如何撤销一个操作。
- 用于事务回滚,确保事务的原子性。
- 用于MVCC,支持读操作在不加锁的情况下看到数据的旧版本。
- Redo Log(重做日志)
- 用途:用于实现事务的持久性,确保事务提交后即使系统崩溃也能恢复数据。
- 特点:
- 记录的是物理修改,即对数据页的具体修改内容。
- 用于事务提交时将日志写入磁盘,确保数据的持久性。
- 用于系统崩溃后的恢复操作,确保数据的一致性。
- Binlog(二进制日志,是server层的)
- 用途:用于记录所有更改数据库的SQL语句(如
INSERT、UPDATE、DELETE),用于主从复制和数据恢复。 - 特点:
- 记录的是逻辑修改,即SQL语句本身。
- 用于主从复制,从服务器通过读取主服务器的Binlog来同步数据。
- 用于数据恢复,可以通过解析Binlog恢复数据。
简单总结
- Undo Log:用于事务回滚和MVCC,记录逻辑修改的逆操作。
- Redo Log:用于事务持久性和崩溃恢复,记录物理修改。
- Binlog:用于主从复制和数据恢复,记录逻辑修改的SQL语句。
在从redologbuffer持久化到硬盘文件的时候,其实是会先将数据写入到OS cache,这个是在内存中的,是为了保证内存和硬盘的传输速率问题,但是有个参数innodb_flush_log_at_trx_commit取值(0、1、2),当为0的时候传输速度最快但是安全性最低,这也算MYSQL优化的一种手法,这里学习这种思想即可,我认为学了这些底层原理后,这些配置参数自然就能看懂了。相比1 TPS提升约为57.2%
6、深度分页问题
深度分页就是在前端如果需要按照时间进行排序每页显示20条数据时候,选择到末尾或厚点很多页时,由于不知道查询的位置,所以会排序后从开始到结束一个一个查询,导致查的非常慢。
(当深度分页时offset较大,性能会显著下降,进而影响查询性能)
前提条件:每次分页操作时,前端会记录最后一个数据的相关排序字段和id,然后交由后端; 注意覆盖索引,将需要排序的字段设置索引
-
解决这个问题还需要结合当前数据库业务,如果数据库中数据本身就是有序的,或主键id和需要排序字段之间是有某种关系的话,就可以直接堆主键id进行排序
1
2
3select t.* from (
select * from table1 order by id limit offest, page_size
) t; -
使用前端传递的记录值
这种方式需要创建 组合索引 且注意要考虑 最左前缀问题
1
2
3
4
5EXPLAIN SELECT id, title, release_date, score
FROM movie
WHERE (release_date, id) < ('2023-09-08', 99999)
ORDER BY release_date DESC, id DESC
LIMIT 20;
7、最左前缀
当创建一个联合索引(index1, index2 ,index3),当查询语句时候最左侧必须包含index1,否则索引会失效
Mysql8.0提出了跳跃查表, 优化了查询性能,使得最左前缀有一定的改善
8、MVCC
多版本并发控制,是事务的隔离级别中的一种表现形式。undolog记录事务版本、readview判断对当前事务的可见性
每一个事务的内部sql会创建三个隐藏字段:trx_id(修改数据事务id)、roll_pointer(回滚指针)、row_id(在无主键id是才会创建)
read_view中维护了三个字段:
已提交的事务
在事务的隔离级别中
- 读未提交:直接修改数据源,出现脏读现象,这里没有使用MVCC进行控制
- 读已提交:使用MVCC,在事务中每次查询都会创建一个ReadView,根据readview去对照undolog
- 可重复读:使用了MVCC,在事务中多次查询都只会创建一个ReadView,从而使得同一个事务中读取的数据是一样的
- 串行化:使用了表锁,没有使用MVCC机制
总结:MVCC就是使用undolog+readview的CAS自旋锁的一种实现,是一种乐观锁的表现
9、锁
Mysql中锁包括共享锁、排他锁、行锁、表锁、间隙锁、
当使用间隙锁时候,会锁住当前插入区间的锁,可以在可重复读的事务隔离级别中使用MVCC机制 + 间隙锁 解决幻读问题
10、谈谈Mysql中事务(美团一面)
Mysql中通过事务的ACID,包括原子性、一致性、隔离性、持久性进行保证。
- 底层是使用undolog + MVCC可以保证事务的原子性、
- 通过行锁 + 间隙锁实现了事务的隔离性
- 使用redolog实现了事务的持久性
- 一致性是多方面进行掌握,通过AID实现了C
11、Mysql分库分表(大数据项目面经)
垂直分库、水平分表
正常情况下公司不会进行分库,而是直接采用分表
首先数据都需要有一个唯一的id
- 分表
- 第一种采用对id进行取余 %,落在不同的表中
- 第二种比如企业的租户id这种,对于不同的公司进行不同的策略,小公司用公共表,大公司独立分出来,每次请求带上租户id
- 分库
- 采用雪花算法
- 一般不用
12、如何优化慢SQL
- 可以先开启慢查询日志
- 使用mysqldumpslow分析慢查询日志,然后定位到sql和表
- 使用explain,看下面字段:
- type:避免不是all或index
- rows:值越小越好
- key:是否走索引
- 要考虑是不是最左前缀发生或者模糊查询%放到了前面
- 查看是否数据量大于两千万了,如果大于两千五要考虑是不是要分库分表。
13、树形表
对于一个树形表,比如在前端需要获取一个树形表中多分类的,有两种解决方案
-
采用自关联子查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18select
one.id one_id,
one.name one_name,
one.parentid one_parentid,
one.orderby one_orderby,
one.label one_label,
two.id two_id,
two.name two_name,
two.parentid two_parentid,
two.orderby two_orderby,
two.label two_label
from course_category one
inner join course_category two on one.id = two.parentid
where one.parentid = 1
and one.is_show = 1
and two.is_show = 1
order by one.orderby,
two.orderby -
采用递归查询
1
2
3
4
5
6with recursive t1 as (
select * from course_category p where id= '1'
union all
select t.* from course_category t inner join t1 on t1.id = t.parentid
)
select * from t1 order by t1.id, t1.orderby
这两种方案中,自关联子查询的应用场景是如果有已知查询的层级时候可以采用自关联子查询,递归查询的使用场景是不知道有多少种类别的时候可以采用
四、JVM
1、谈谈你对JVM的理解
JVM是Java运行时环境的核心组件,它为Java程序提供了运行所需的环境,主要作用是将Java字节码转换成机器码,从而在不同的操作系统和硬件平台运行程序
2、JVM的内存模型
3、强引用、软引用、弱引用、虚引用
- 强引用
- 直接使用new出来的,当JVM发生OOM时候宁愿抛出异常也不会回收
- 软引用
- 使用SoftReference进行包装的,当JVM发生OOM内存溢出时候,会将这个对象列入回收范围内,如果回收后依然没有足够的内存,则会抛出异常
- 弱引用
- 使用WeakReference进行包装,无论是否OOM,如果类中一个资源为Null,则也会进行垃圾回收
- 虚引用
- 使用PhantomReference进行包装,主要用于跟踪垃圾回收过程
4、逃逸分析
当前创建的对象只有在当前类中使用,那么就可以直接将创建的对象放到栈中,避免放到堆空间中垃圾回收,加快运行速度
5、ThreadLocal
采用无锁的方式,给每个线程创建自己的变量副本,其中ThreadLocal是由ThreadLocalMap
其中每个Thread中有ThreadLocalMap组成,其中ThreadLocalMap是由多个Key-Value组成,当ThreadLocal调用set、get方法时候就是对ThreadLocalMap中key进行设置,其中key是弱引用,当栈中ThreadLocal被销毁时候,会将ThreadLocalMap中key销毁,但是value不会销毁,所以需要手动进行remove
当在多线程状态下尤其要注意,要设置remove,防止OOM内存溢出
6、诊断工具
- Arthas
- 首先运行java -jar的Arthas的工具
- 然后在Arthas中找到运行的程序,属于对应的序号
- 进入这里的程序然后输入dashboard进一步查看各个进程、CPU、JVM信息等
- 然后找到出现异常的线程
- thread -b
- ognl:可以直接修改线上系统变量的值
7、JVM调优------堆内存模型
年轻代(伊甸园区、S0、S1)、老年代
假设堆内存大小(-Xmx)为6GB,那么:
- 新生代:占堆内存的1/3,即2GB。
- 伊甸园:占新生代的80%,即1.6GB。
- 每个幸存者区(S0和S1):各占新生代的10%,即0.2GB。
- 老年代:占堆内存的2/3,即4GB。
新创建的对象会放到伊甸园区,当伊甸园区满时会进行Minor GC,将数据放到S0、S1中,并且将放到S0、S1中的年龄 +1。注意:当传到S0、S1中的内存量>50%的S0、S1时候会直接放到老年代
当S0、S1满时候会将数据放到老年代,或当S0、S1年龄大于16岁时候放到老年代中。
当老年代中内存满时候,会发生Full GC
这里调优可以看到,可以将年轻代中的内存量调大,减少Full GC
8、双亲委派机制
当一个类加载器需要加载一个类的时候,会先让他的父类加载器去加载,如果父类加载器无法加载,再让子类加载器去加载
- 避免重复加载:确保一个类在JVM中只被加载一次,避免重复加载同一个类
- 保护核心类库:防止用户自定义的类覆盖Java核心类库中的类,保护的核心类库的安全性
9、三色标记法
是可达性分析的一种表现形式,主要用于GC回收时,白色代表非垃圾、灰色代表未被回收、黑色代表回收
五、基础篇
1、创建对象的三种方式
- new
- 反射
- 通过序列化和反序列化
- 通过Clone克隆,属于浅拷贝
2、对象循环引用
对象a中引入b、对象b中引用a。这种会导致内存泄漏(GC无法回收)和序列化问题
设计层面
- 重新审视类的设计,尽量避免不必要的相互引用
- 使用组合代替继承可以减少类之间的耦合度,比如将集成关系中父类变成子类的一个成员变量,从而降低循环引用的风险。
代码层面
-
手动将引用设置为
null,这样可以打破循环引用。 -
使用弱引用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import java.lang.ref.WeakReference;
class A {
WeakReference<B> b;
}
class B {
WeakReference<A> a;
}
public class Main {
public static void main(String[] args) {
A a = new A();
B b = new B();
a.b = new WeakReference<>(b);
b.a = new WeakReference<>(a);
}
}
六、微服务
服务拆分、服务治理、 高可用保障
1、Nacos
用于服务注册和配置管理,可以实现配置热更新和网关路由表的热更新
默认端口是8848/nacos
-
服务注册
由Spring项目直接发送到Nacos中,由Nacos直接进行注册
-
配置管理
需要先创建共享配置,然后在springcloud项目中的resource下新建bootstrap.yaml文件加载当前的共享配置
-
环境隔离
为了解决开发、测试、发布环境,需要使用nameSpace进行
2、OpenFeign
可以简化服务之间的Http调用,可以实现负载均衡,依赖于Nacos这种注册中心
-
开启OpenFeign
在需要引用其它微服务的启动类上添加
EnableFeignClients -
撰写Feign客户端
1
2
3
4
5
6
public interface ItemClient {
List<ItemDTO> queryItemByIds( Collection<Long> ids);
}
3、Gateway
3.1、网关
-
网关,前端发送请求可以直接发送到网关,由网关决定路由到哪个微服务中,需要在配置文件中添加路由表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23server:
port: 80
spring:
application:
name: gateway
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
gateway:
routes:
- id: user-route
uri: lb://user-service # lb = 负载均衡
predicates:
- Path=/api/user/** # 断言
filters:
- StripPrefix=1 # 去掉 /api/user
- id: order-route
uri: lb://order-service
predicates:
- Path=/api/order/**
filters:
- StripPrefix=1浏览器访问
http://gateway/api/user/profile/1→ Gateway 自动负载均衡到user-service实例,零代码。- Route(路由)
由 ID + 目标 URI + Predicate 集合 + Filter 集合组成。 - Predicate(断言)
判断请求是否匹配该路由;Spring Cloud Gateway 内置 11 种:Path、Method、Header、Query、Cookie、Time、RemoteAddr、Host、CloudFoundryRoute、Weight、JWT。
可 AND/OR 组合,也支持自定义。 - Filter(过滤器)
对请求/响应进行横切面处理;分 GatewayFilter(局部) 与 GlobalFilter(全局)。
责任链模式,Ordered 排序,前后置可插拔。
- Route(路由)
3.2、限流
Gateway 限流 = “内置过滤器 + Redis 令牌桶 + Lua 原子脚本”,一条 YAML 就能给整个微服务集群加上 分布式、可扩展、可观测 的流量闸门
4、Sentinel
用于服务限流、线程隔离、熔断,保护了不是由几个微服务挂了而导致全部的微服务宕机
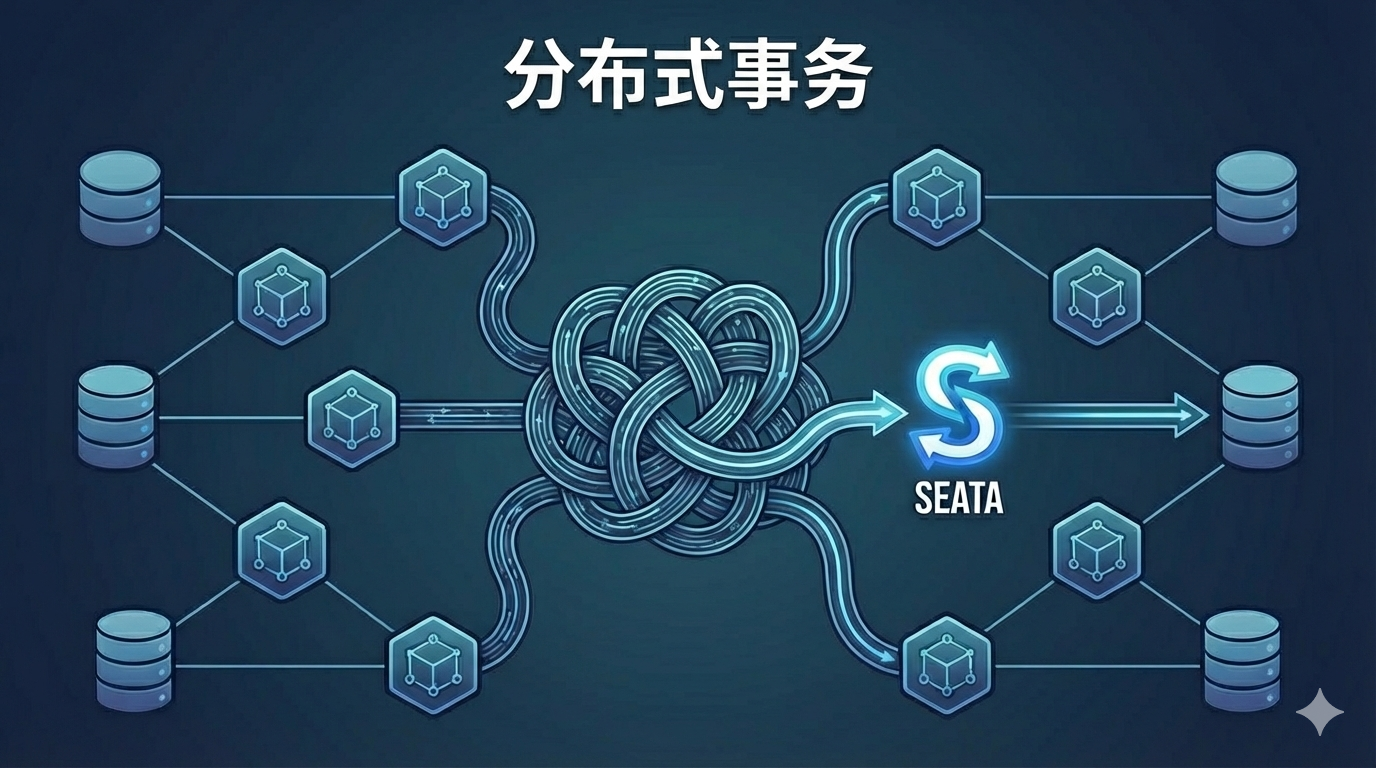
5、Seata
用于解决分布式事务下的各种问题,分为TC(事务协调者)、TM(事务管理器)、RM(资源管理器)
- XA模式,使用两模式提交,当执行事务后不进行提交,而是所有事务提交之后进行提交或回滚,具有 强一致性
- AT模式,使用两模式提交,当执行事务后直接进行提交,并且记录到undolog中,当所有事务提交完毕之后会判断,如果所有分支事务无误则不进行操作,若所有分支事务有误则进行操作使用undolog进行回滚,会使用 全局锁
- TCC模式,Try、Confirm、Cancel,三模式提交,注意Confirm和Cancel中会有幂等的问题,需要进行进一步的处理,是依赖于补偿操作,也可以将一些没有事务的数据库比如redis也做成一个带有事务操作的数据库
6、Sentinel限流和Gateway限流的区别
一开始可以使用固定窗口进行
限流算法的常见方式主要又三种:滑动时间窗口、令牌桶算法、漏桶算法
Gateway采用了基于Redis实现的令牌桶算法
Sentinel内部更加复杂:
- 默认限流模式是基于滑动时间窗口算法,熔断器中采用的也是滑动时间窗口算法
- 限流中排队等待采用的是基于漏桶算法
- 热点参数限流采用令牌桶算法
Sentinel限流
- 对于Warm Up的限流方式,可以设置QPS为1000,冷启动因子为3,预热是汉奸为10秒,那么在一开始会使用1000/3=333个请求进入,随后10秒内逐步加到1000个请求量
七、多线程
1、异步编排
CompletableFuture
脑图:https://www.processon.com/view/link/6638e5d996857d67d2e3e998
在传统FutureTask底层是使用volatile变量保证状态可见性,使用CAS自选锁操作进行无锁状态转换,使用LockSupport进行线程等待和唤醒,避免了传统的synchronized开销
CompletableFuture底层实现了Future接口,并且提供了异步任务(runAsync无返回值、supplyAsync有返回值)、组合处理(anyOf找到运行最快的底层是构建了一个或树、anyAll等全部都执行,底层构建了与树。这两种树都是基于平衡二叉树的)、异步回调(thenRun没有返回值、thenAccept可传参通常五返回值、thenApply作为需要返回值)
异步编排通常需要考虑有异常这种,对于事务其实是不敏感的,所以需要对于上下游接口出现异常要有个兜底策略
1 | import java.util.concurrent.CompletableFuture; |
2、ConcurrentHashMap
ConcurrentHashMap 的线程安全机制主要包括以下几个方面:
- 分段锁(Segment):java7 之前通过将哈希表分成多个 Segment,每个 Segment 是一个独立的锁,减少了锁的竞争。
- 细粒度的锁:在 Java 8 及之后的版本中,提出了Node节点的概念,将hashmap的数据结构变成了数组+链表+红黑树,所以将链表或红黑树变成了一个桶,直接在哈希表的每个桶(bucket)上使用细粒度的锁(synchronized 或 CAS 操作)。
- CAS 操作:在添加、修改、删除节点Node的时候,会使用CAS操作红黑树
- synchronized操作:虽然CAS提供了线程的安全性,但是不能保证全部线程安全,比如在下面场景中就需要用到synchronized保证绝对的线程安全 -> 桶的初始化、红黑树的初始化
3、synchronized
JVM实现:可见性、可重入性、原子性、不公平性、重量级锁
底层使用Monitor监视器,当使用synchronized时候需要将绑定的对象的MarkWord指向Monitor对象的指针。
其中MarkWord中低三位分别表示如下:001(无锁)、101(偏向锁)、000(轻量级锁)、010(重量级锁)、11(GC回收)
锁升级:无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁
偏向锁中不使用Monitor而使用对象头MarkWord、轻量级锁采用Monitor记录锁的状态和线程信息但是不会直接进入重量级锁、重量级锁直接使用Monitor
当在同一个临界资源中使用synchronized,一个线程进入会先在Monitor中作为Owner、其它线程会进入entrylist这种阻塞队列中、当调用wait方法时候需要将对应的线程释放当前锁,并且将当前线程放入到waitset中、当调用sleep不会释放锁,只会阻塞
4、ReentrantLock
JDK实现:可重入性、不可见性、可中断性、公平锁
底层采用双向链表 + int字段的status使用(使用volite原子性修饰)
首节点采用空对象进行存储,后续使用CAS进行检查status并且
5、指令重排
指令重排序(Instruction Reordering) 是编译器、JIT 编译器或 CPU 为了优化性能,在不改变单线程程序语义的前提下,对指令执行顺序进行重新排列的一种优化手段。
| 重排序主体 | 发生阶段 | 说明 |
|---|---|---|
| 编译器(javac) | 编译期 | 在生成字节码时,编译器可能对语句顺序进行优化。 |
| JIT 编译器(C2、Graal 等) | 运行期 | 将字节码编译为机器码时,可能重排指令以提高流水线效率。 |
| CPU 处理器 | 执行期 | 现代 CPU 支持乱序执行(Out-of-Order Execution),可能重排机器指令。 |
指令重排序不会破坏单线程程序的语义,但在多线程环境下,可能导致可见性和有序性问题。
举例:
1 | class ReorderExample { |
在多线程下,语句1 和 语句2 可能被重排序,导致 reader() 线程看到 flag = true 但 a 仍然是 0。
使用 内存屏障(Memory Barrier) 或 happens-before 规则:
| 机制 | 说明 |
|---|---|
volatile |
禁止指令重排序,保证可见性和有序性。 |
synchronized |
保证原子性和可见性,隐含内存屏障。 |
java.util.concurrent 包 |
如 AtomicInteger、ReentrantLock 等,内部使用内存屏障。 |
总结:
指令重排序在 Java 中随时可能发生(编译期、运行期、CPU 层),只要不违反单线程语义;但在多线程环境下,必须通过
volatile、synchronized等机制来防止重排序带来的问题。
6、可见性
可见性是指一个线程堆共享数据进行了修改后,另外一个线程能够直接读到修改后的数据
工作内存和主内存:
- 工作内存是指每个线程私有的内存区域、存储了线程正在操作的变量的副本
- 主内存就是真正的共享变量
通常每个线程会操作工作内存,导致在一定时间内无法更新到主内存
在synchronized和ReentrantLocak中采用了读写屏障进行了优化
同时还可以使用volatile关键字,会直接写入到主内存中
内存屏障:可以防止指令重排
7、AQS
AQS是多线程队列同步器,是Java中实现多种锁(ReentrantLock,CountDownKatch,Semaphore)的一种框架,由两部分组成,一种是双向链表队列用来存正在占有的线程和等待线程(头节点、线程、尾节点组成),一种是int类型的state变量,被volatile所修饰,保证了原子性,0代表没有线程占用,1代表有线程被占用
当第一个线程进来时会通过CAS自旋的方式去修改state变量,如果修改成功则将AQS中获得锁的成员变量exclusiveOwnerThread设置为此线程,当再来一个线程时候通过CAS方式去修改state变量发现修改失败,就会放到队列中,在放入之前还会再确认一遍(这里有种双重检查锁的样子),
八、Elasticsearch
1、基本认识
文档、词条、索引、映射
- 文档就是每一条数据
- 词条就是按照语义进行分词后的每个词语
- 索引就是相同文档的集合(就是Mysql中表)
- mapping映射就是索引中文档的字段约束信息(就是将哪个字段进行分词)
- type:字段类型
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
倒排索引
对文档内容进行分词,对词条创建索引,并且记录词条所在文档的id。查询时先根据词条查询到文档id,而后根据文档id查询文档
这和正排索引中使用id进行逐行查询数据不同,就是一种非聚簇索引的体现
IK分词、自定义词典
对于中文需要使用IK分词器进行分词,并且可以在config中上传自己的词典
九、MinIo
“4+2 纠删码 = 4 个未知数 + 2 条方程”
可以将丢失的数据找回
1 | minio.Client进行操作 |
注意下载需要计算源文件和下载文件的完整性,需要计算其MD5值看看是不是匹配
1、分片上传
将一个大文件,分片的上传到minio中,上传完毕后再进行合并
2、断点续传
- 首先前端会使用
SparkMD5分块增量或抽样的计算视频的MD5值,然后使用Blob.slice(start, end)零拷贝的方式将视频分块,然后将每块当成独立的文件进行上传
3、秒传
前端每次上传时候会计算MD5值,然后和后端进行比较,如果存在则直接不用上传
分片上传、断点续传、秒传
前端
- 首先需要对文件进行分片使用Blod中file.silce设置分片大小
- 然后根据分好的片,选取第一个和最后一个切片的内容,中间剩余的切片分别再前面和后面和中间取n个字节使用SparkMD5计算参与计算的切片的哈希值
sequenceDiagram
actor 前端 as Browser
participant 后端 as Backend Service
participant Redis
participant MinIO
title 场景三:断点续传流程
前端->>前端: 1. 计算文件 MD5
前端->>前端: 2. 检查 localStorage, 发现已保存的
uploadId 和已完成分片列表 (doneParts)
Note over 前端: 3. 开始上传任务
loop 对于文件的每一个分片 (partNumber)
alt 分片已在 doneParts 列表中
前端->>前端: 4a. 跳过此分片,不发起任何请求
else 分片未完成
Note over 前端, 后端: 4b. 对未完成的分片,执行与首次上传相同的流程
前端->>后端: POST /api/upload/presign (含 uploadId, partNumber)
后端-->>前端: 返回预签名 URL
前端->>MinIO: PUT {presigned_url}
MinIO-->>前端: 200 OK (响应头含 ETag)
前端->>后端: POST /api/upload/chunk/confirm (...)
后端->>Redis: 更新并保存 UploadSession
后端-->>前端: 200 OK
前端->>前端: 将 partNumber 加入 doneParts 并更新 localStorage
end
end
Note over 前端, 后端: 5. 所有分片都完成后,执行与首次上传相同的合并流程
前端->>后端: POST /api/upload/complete (含 uploadId)
后端->>MinIO: CompleteMultipartUpload
MinIO-->>后端: OK
后端->>Redis: 保存指纹,删除会话
后端-->>前端: 返回最终 FileInfo
十、XXL-JOB
十一、DDD领域驱动设计
是一种以业务领域为中心的软件架构方法论,简单来说当发现需要修改业务规则的时候,只需要调整领域代码,而无需修改Controller或DAO,这才是DDD的真实落地
数据模型
- 贫血模型:MVC的实体类中国通常只包含getter\setter,业务逻辑全在service中
- 充血模型:DDD的实体类中国包含业务规则和行为,数据字段仅作为实体状态的载体
十二、JVM
1、什么是JVM
jvm就是java的虚拟机,其有以下功能:
-
解释和运行:对java字节码文件的指令实时的解释成机器码,让计算机执行
- 类加载器
- 运行时数据区
- 执行引擎
- 本地接口
-
内存管理:自动为对象、方法分配内存;自动的垃圾回收机制
-
即时编译:对热点代码进行优化,提升执行的效率
- 方法内联
- 逃逸分析
2、类加载器
类加载器是指将java的字节码文件加载到内存的加载器,其在jdk8及其以前和之后架构不一样
JDK8及其以前:
- C++编写:启动类加载器Bootstrap
- Java编写:扩展类加载器Extension、应用程序类加载器Application、自定义类加载器
JDK9及其之后:
都由Java编写改成了 -> 启动类加载器、平台类加载器、应用程序类加载器
3、双亲委派模型
**含义:**当一个类加载器接收到了加载类的的任务的时候,会自底向上询问其父类加载器是否加载过,如果加载过即返回,如果没有加载过会继续向上查找当查找到启动类加载器的时候如果还没有被加载过,那么就会从启动类加载器开始自顶向下进行加载,查看是否在自己所定义的路径上有该类,如果存在即加载,不存在就继续向下加载
**作用:**保证了类加载的安全性,防止jdk中自带的一些类被别的类加载器去篡改;避免了重复加载


这里记录了我在学习过程中积累的经验和一些开源项目的分享。感谢您的访问,希望您能在这里找到您感兴趣的内容。祝您生活愉快!